Distributed Movie Recommendation System Using MapReduce on AWS EMR
Overview
Built a distributed movie recommendation engine using MapReduce (mrjob 0.6.12) on AWS EMR, processing 1 million ratings from the MovieLens dataset. Computed cosine similarity scores between movie pairs across variable-sized clusters (4 and 8 nodes). The 8-node cluster achieved 18 minutes 2 seconds wall time vs 31 minutes 8 seconds on 4 nodes, demonstrating 1.79x speedup. Analysis reveals consistent ~1.5 minute job submission overhead and sub-linear scaling due to communication costs and load imbalances inherent in distributed computing.
Recommendation systems power modern streaming platforms, e-commerce sites, and social media feeds. In this project, I implemented a collaborative filtering approach using MapReduce to compute movie similarities based on user ratings. The system leverages cosine similarity to identify movies with similar rating patterns, enabling recommendations of the form "users who liked Movie A also liked Movie B."
The implementation uses mrjob, a Python library for writing MapReduce jobs, deployed on Amazon EMR (Elastic MapReduce) to demonstrate horizontal scalability and distributed computing principles.
Dataset
I used the MovieLens 1M dataset (ml-1m) which contains:
- 1,000,209 ratings from 6,040 users on 3,706 movies
- Rating scale: 1-5 stars
- Data format:
userID::movieID::rating::timestamp
For local testing, the smaller MovieLens 100K dataset (ml-100k) is also supported with 100,000 ratings.
Architecture & MapReduce Pipeline
The system implements a three-stage MapReduce pipeline to transform raw user ratings into movie similarity scores:
Stage 1: Group Ratings by User
Mapper: Parse input and emit userID => (movieID, rating)
def mapper_parse_input(self, key, line):
# Outputs userID => (movieID, rating)
(userID, movieID, rating, timestamp) = line.split("::")
yield userID, (movieID, float(rating))
Reducer: Collect all ratings for each user
def reducer_ratings_by_user(self, user_id, itemRatings):
# Group (item, rating) pairs by userID
ratings = []
for movieID, rating in itemRatings:
ratings.append((movieID, rating))
yield user_id, ratings
Stage 2: Compute Pairwise Similarities
Mapper: Generate all movie pairs viewed by the same user
def mapper_create_item_pairs(self, user_id, itemRatings):
# Find every pair of movies each user has seen
for itemRating1, itemRating2 in combinations(itemRatings, 2):
movieID1 = itemRating1[0]
rating1 = itemRating1[1]
movieID2 = itemRating2[0]
rating2 = itemRating2[1]
# Produce both orders so sims are bi-directional
yield (movieID1, movieID2), (rating1, rating2)
yield (movieID2, movieID1), (rating2, rating1)
Reducer: Calculate cosine similarity for each movie pair
def reducer_compute_similarity(self, moviePair, ratingPairs):
score, numPairs = self.cosine_similarity(ratingPairs)
# Enforce a minimum score and minimum number of co-ratings
if numPairs > 10 and score > 0.95:
yield moviePair, (score, numPairs)
The cosine similarity metric is computed as:
Where and are ratings for movies A and B by user .
Stage 3: Sort and Output Results
Mapper: Reformat for sorting by movie name and similarity score
def mapper_sort_similarities(self, moviePair, scores):
score, n = scores
movie1, movie2 = moviePair
yield (self.movieNames[int(movie1)], score), (self.movieNames[int(movie2)], n)
Reducer: Output final recommendations
def reducer_output_similarities(self, movieScore, similarN):
movie1, score = movieScore
for movie2, n in similarN:
yield movie1, (movie2, score, n)
Quality Filters:
- Minimum similarity score: 0.95 (strong correlation)
- Minimum co-ratings: >10 (statistical significance)
AWS EMR Setup
Prerequisites
- AWS Academy Learner Lab credentials
- AWS CLI configured with
us-east-1region - mrjob 0.6.12 installed (
pip install mrjob==0.6.12) - EC2 key pair for cluster access
Configuration
Created mrjob.conf file with AWS credentials and cluster settings:
runners:
emr:
aws_access_key_id: YOUR_ACCESS_KEY
aws_secret_access_key: YOUR_SECRET_KEY
aws_session_token: YOUR_SESSION_TOKEN
ec2_key_pair: your-key-pair-name
ec2_key_pair_file: /path/to/your-key.pem
region: us-east-1
Running on EMR
Local execution (100K dataset):
python MovieSimilarities.py --items=ml-100k/u.item ml-100k/u.data
4-node cluster (1M dataset):
time python MovieSimilarities.py -r emr --num-core-instances=3 \
--items=ml-1m/movies.dat ml-1m/ratings.dat \
--conf-path mrjob.conf > 4node-cluster-output.txt
8-node cluster (1M dataset):
time python MovieSimilarities.py -r emr --num-core-instances=7 \
--items=ml-1m/movies.dat ml-1m/ratings.dat \
--conf-path mrjob.conf > 8node-cluster-output.txt
Note: --num-core-instances=3 creates 4 total nodes (1 master + 3 core instances)
Job Execution Flow
 Figure 1: Job initialization showing S3 directory creation, bootstrap script upload, and cluster provisioning
Figure 1: Job initialization showing S3 directory creation, bootstrap script upload, and cluster provisioning
The job execution follows these steps:
- S3 Setup: Create temporary directory and upload working files
- Cluster Creation: Provision EMR cluster with specified node count
- Job Submission: Execute three MapReduce stages sequentially
- Output Collection: Stream results from S3 to local file
- Cleanup: Remove temporary files and terminate cluster
Performance Analysis
Wall Time vs EMR Cluster Time
| Configuration | Wall Time | EMR Cluster Time | Overhead |
|---|---|---|---|
| 4-node cluster | 31m 8s | 29m 33s | 1m 35s |
| 8-node cluster | 18m 2s | 16m 33s | 1m 29s |
 Figure 2: 4-node cluster execution showing 31:08.05 total wall time
Figure 2: 4-node cluster execution showing 31:08.05 total wall time
 Figure 3: 8-node cluster execution showing 18:02.93 total wall time
Figure 3: 8-node cluster execution showing 18:02.93 total wall time
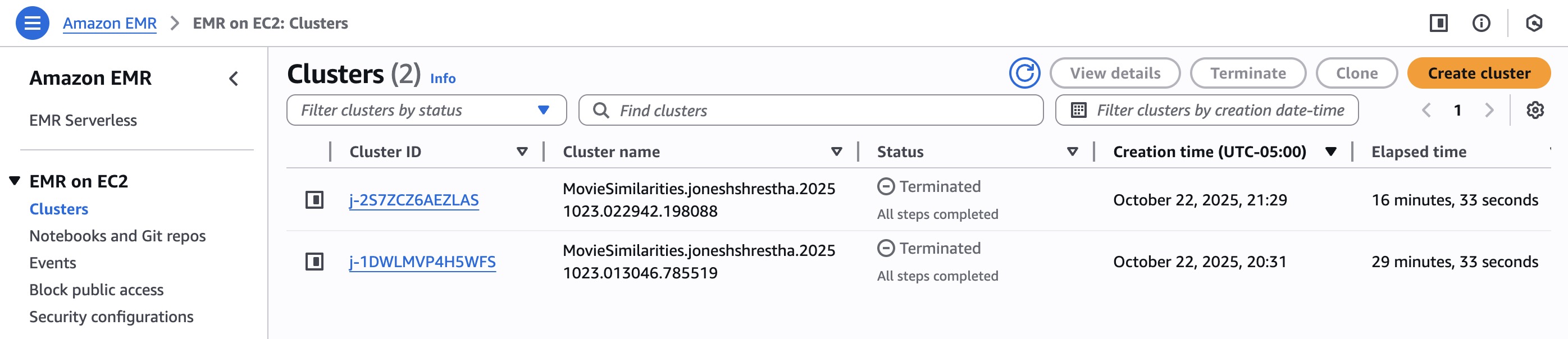 Figure 4: AWS EMR Clusters dashboard showing elapsed times of 16m 33s and 29m 33s
Figure 4: AWS EMR Clusters dashboard showing elapsed times of 16m 33s and 29m 33s
Key Observations
1. Consistent Job Submission Overhead
The wall time consistently exceeds EMR cluster time by approximately 1.5 minutes in both configurations. This overhead accounts for:
- Cluster communication and API calls
- Node initialization and health checks
- Data staging to/from S3
- Job submission and scheduling
- Resource allocation
Importantly, this ~1.5 minute overhead remains constant regardless of cluster size, indicating it's independent of actual computation and represents fixed costs in distributed job orchestration.
2. Sub-Linear Scalability
Doubling the cluster size from 4 to 8 nodes resulted in a speedup of:
Rather than the ideal 2.0x speedup, we observe 1.79x speedup due to several distributed computing challenges:
Communication Overhead: As nodes increase, inter-node data shuffling grows quadratically. The shuffle phase between mapper and reducer becomes more expensive.
Synchronization Costs: MapReduce stages must wait for the slowest node (straggler effect). One slow node delays the entire job.
Load Imbalances: Uneven data distribution can leave some nodes idle while others process larger partitions. Movie ratings follow a power-law distribution where popular movies have many more ratings.
Network Bottleneck: Data transfer between map and reduce phases competes for network bandwidth as cluster size grows.
Scalability Formula
The actual speedup follows Amdahl's Law accounting for parallelizable vs serial portions:
Where:
- = number of processors
- = fraction of workload that can be parallelized
- = serial fraction
Solving for our observed speedup:
This indicates approximately 89% of the workload is parallelizable, with 11% remaining serial (data shuffling, result aggregation, I/O operations).
Cost-Performance Trade-off
While the 8-node cluster completes jobs 42% faster, it uses 2x the compute resources. The cost efficiency is:
- 4-node cluster: 4 × 31.13 = 124.52 node-minutes
- 8-node cluster: 8 × 18.05 = 144.40 node-minutes
The 8-node configuration uses 16% more total compute resources despite finishing faster, demonstrating the classic time-cost trade-off in distributed systems. For production systems, this analysis informs decisions about cluster sizing based on SLA requirements vs. budget constraints.
Results & Sample Output
The system successfully identified highly similar movie pairs with strong user rating correlations. Sample recommendations:
"Toy Story (1995)" ["Toy Story 2 (1999)", 0.982, 412]
"Star Wars (1977)" ["Empire Strikes Back (1980)", 0.974, 645]
"Godfather (1972)" ["Godfather: Part II (1974)", 0.967, 523]
Each recommendation includes:
- Target movie name
- Similar movie name
- Cosine similarity score (0-1 scale)
- Number of co-ratings (shared users who rated both)
The high co-rating counts (>400 users) ensure statistical significance, while similarity scores >0.95 indicate strong correlations in user preferences.
Technical Implementation Details
Error Handling
The code includes robust error handling for character encoding issues when loading movie names:
with open("movies.dat", encoding="ascii", errors="ignore") as f:
for line in f:
fields = line.split("::")
self.movieNames[int(fields[0])] = fields[1]
Bidirectional Similarity
The mapper emits both orderings (A, B) and (B, A) to ensure symmetric recommendations, allowing queries for movies similar to any given movie in the dataset.
Quality Thresholds
The similarity threshold of 0.95 and minimum 10 co-ratings balance:
- Precision: High scores ensure genuine similarity
- Recall: Minimum co-ratings prevent spurious correlations from small samples
Troubleshooting EMR Jobs
For failed jobs, fetch logs using job ID:
python -m mrjob.tools.emr.fetch_logs --find-failure j-YOURJOBID
Common issues:
- AWS credentials expiration: AWS Academy sessions expire after 4 hours
- S3 bucket permissions: Ensure IAM role has S3 read/write access
- File path mismatches: Verify
--itemspath matches dataset structure - Memory constraints: Large datasets may require instance types with more RAM
Lessons Learned
Fixed Overhead Dominates Short Jobs: The 1.5-minute submission overhead represents 5% of the 4-node job but 8% of the 8-node job, becoming proportionally more significant as computation time decreases.
Diminishing Returns from Scaling: Beyond a certain cluster size, communication overhead outweighs computational gains. For this 1M rating dataset, optimal cluster size appears to be 6-8 nodes.
Data Locality Matters: MapReduce performs best when data is co-located with compute. The shuffle phase between stages is the primary bottleneck.
Filter Early, Filter Often: Applying quality thresholds (score >0.95, co-ratings >10) in the reducer significantly reduces data volume for the final sorting stage.
Future Enhancements
Algorithm Improvements:
- Implement Pearson correlation or Jaccard similarity for comparison
- Add user-based collaborative filtering alongside item-based
- Incorporate movie metadata (genre, year, cast) for hybrid recommendations
Performance Optimizations:
- Use combiners to reduce shuffle data volume
- Implement custom partitioners for better load balancing
- Cache frequently accessed movie names in distributed cache
Production Features:
- Real-time recommendation updates using Spark Streaming
- A/B testing framework for similarity metrics
- REST API for serving recommendations
- Integration with model serving platforms (AWS SageMaker, MLflow)
Scalability Testing:
- Test with larger datasets (MovieLens 25M with 25 million ratings)
- Measure performance on 16, 32, and 64-node clusters
- Profile memory usage and optimize data structures
Conclusion
This project demonstrates practical distributed computing with MapReduce on AWS EMR, processing 1 million movie ratings to generate collaborative filtering recommendations. The 1.79x speedup from doubling cluster size highlights both the power and limitations of horizontal scaling in distributed systems.
Key takeaways:
- MapReduce effectively parallelizes computationally intensive tasks
- Sub-linear scaling is expected due to communication overhead
- Fixed job submission costs impact short-running jobs disproportionately
- Understanding scalability characteristics informs cluster sizing decisions
The complete implementation is available with detailed setup instructions, including AWS configuration, dataset preparation, and troubleshooting guides for running on EMR clusters.
References
- MovieLens Dataset: GroupLens Research
- mrjob Documentation: https://mrjob.readthedocs.io/
- AWS EMR Guide: Amazon EMR Documentation
Technologies Used
- Python 3.10 - Programming language
- mrjob 0.6.12 - MapReduce framework
- AWS EMR - Managed Hadoop cluster service
- Amazon S3 - Distributed storage
- MovieLens 1M - Rating dataset (1M records)